やねうら王で使えるNNUE型評価関数をGPU を用いて学習できるnnue-pytorchの環境構築に成功したので方法を共有します。
nnue-pytorchはもともとチェス用に開発されましたが、将棋AIたぬきシリーズ作者のnodchipさんにより将棋用にカスタマイズされたバージョンが公開されています。
目標
nnue-pytorchから将棋AI学習用棋譜 データshogi_hao_depth9 を読み込み、標準NNUEモデルを学習し、やねうら王で動作させる。
必要な環境
Windows 11
Windows 10でも行けると思います。Linux は使えません。Parallel Patterns Library (ppl.h)というMSVC専用のライブラリが使われているためです。
NVIDIA のGPU
検証環境ではRTX 4070を用いました。
最近のPyTorchはCUDAバイナリが同梱されているので、PyTorchのバージョンに合わせたCUDAのインストールは不要と思われます。
1TB以上のディスク
棋譜 のダウンロード・加工に必要です。SSD が望ましいです。筆者はNAS 上のHDDを使う必要があり、余分に時間がかかりました。
学習用データの準備
ダウンロード
nodchipさんが公開している棋譜 データをダウンロードします。約300GBあり、gitの管理用データとあわせてディスク容量が約600GB必要です。
データセットの説明
事前にHugging Face のユーザ登録・SSH 公開鍵登録 https://huggingface.co/settings/keys が必要です。
以下のコマンドで、データセット をダウンロードします。約300GBあるため、回線速度により相当な時間がかかります。
git lfs install
git clone git@hf.co:datasets/nodchip/shogi_hao_depth9
シャッフル
ダウンロードしたデータセット は、 PackedSfenValue という形式で局面とその(深さ9で探索した際の)評価値などが1局面当たり40バイトで記録されています。1ファイルは約300MB、ファイル数は1016個あります。データセット を学習用と評価用に分け、さらにそれぞれをシャッフルします。シャッフルは2つの観点で必要です。1つは、ファイル内の連続する局面は同じ対局から生じたものであるため、学習の安定性のためです。もう1つは、静止探索(qsearch)を適用するためです。探索部が局面Xを評価する場合、もしXが駒の取り合いの最中の局面であった場合、静止探索により駒の取り合いが終わった局面Yに対して評価関数を計算します。そのため、データセット 中に局面Xがある場合、それを局面Yに置換し、局面Yと評価値のペアとして評価関数を学習する必要があります。
データセット の説明にある通り、シャッフルも静止探索も適用されていないため、適切な学習のためには単純に40バイトのレコードをランダムにシャッフルするだけではなく、局面を理解したうえで静止探索を適用する機構を持ったシャッフルプログラムが必要です。
セットアップ
シャッフルを行うプログラムも、nodchipさんのリポジトリ にあります。注意点として、 tanuki-dr4-learner ブランチを選ぶ必要があります。他のブランチでは、必要な機能が搭載されていません。
github.com
これのビルドに少々難儀したため、「独自ビルド」の章で作成したビルド済みバイナリを置いておきます(オリジナル版に対して修正が入っています)。
github.com
ここでは、 YaneuraOu_NNUE-evallearn-g++-sse42.exe を使う想定でコマンドを記述します。CPUにより、avx2, zen3などを使うとよりパフォーマンスが上がる可能性があります。
静止探索を行うために、評価関数ファイルが必要です。このバイナリでは標準NNUE形式が使われますので、その1つとしてnodchipさんが公開している『Háo』評価関数を用います。
Release tanuki-.halfkp_256x2-32-32.2023-05-08 · nodchip/tanuki- · GitHub
ここから tanuki-.halfkp_256x2-32-32.2023-05-08.7z をダウンロード、展開し、以下のディレクト リ構造になるように配置します。
- YaneuraOu_NNUE-evallearn-g++-sse42.exe
- eval
- nn.bin
ちなみに、Windows 11では標準機能で7z (7-zip )が解凍できます。
実行
シャッフルプログラムは、1つのフォルダにあるすべてのファイルをシャッフルして結合し、別の1ファイルを出力する仕様になっています。事前に、学習(train)と評価(val)ディレクト リにファイルを分けておきます。ここでは、ファイル名に thread_index=126 とある8個のファイルを評価用に、残りの1008個を学習用にします。(path/toの箇所は適宜置き換えてください)
cd path\to\shogi_hao_depth9
mkdir val
move "kifu.tag=train.depth=9.num_positions=1000000000.start_time=*.thread_index=126.bin" val
mkdir train
move *.bin train
以下のコマンドで、シャッフルを実行します。ディスクの速度によりますが、数時間かかります。筆者は論理16コア、RAM容量32GBのマシンで動かしましたが、容量が小さい場合はバッファサイズの調整が必要かもしれません。
cd path\to\tanuki-
YaneuraOu_NNUE-evallearn-g++-sse42.exe usi , Threads 15 , EvalDir eval , KifuDir path\to\shogi_hao_depth9\val , KifuReaderBufferSize 2147483647 , KifuWriterBufferSize 268435456 , ShuffledKifuDir path\to\shogi_hao_depth9\val_shuffled , ShuffledMinPly 1 , ShuffledMaxPly 9223372036854775807 , ShuffledMinProgress 0.0 , ShuffledMaxProgress 1.0 , ApplyQSearch true , isready , usinewgame , shuffle_kifu , quit
YaneuraOu_NNUE-evallearn-g++-sse42.exe usi , Threads 15 , EvalDir eval , KifuDir path\to\shogi_hao_depth9\train , KifuReaderBufferSize 2147483647 , KifuWriterBufferSize 268435456 , ShuffledKifuDir path\to\shogi_hao_depth9\train_shuffled , ShuffledMinPly 1 , ShuffledMaxPly 9223372036854775807 , ShuffledMinProgress 0.0 , ShuffledMaxProgress 1.0 , ApplyQSearch true , isready , usinewgame , shuffle_kifu , quit
これで、シャッフル済みデータセット ファイル( path\to\shogi_hao_depth9\{train,val}_shuffled\shuffled.bin )が得られました。
独自ビルド
シャッフルプログラムには、進行度を推定し、進行度が特定の範囲の局面だけを出力する機能がついているのですが、そのためには進行度推定モデルファイル"progress.bin"が必要でした。公開されているファイルが見当たらなかったため、進行度推定を使用しない場合はこのファイルがなくてもシャッフルを行えるよう改良を行いました。その結果が筆者のリポジトリ にあります。
GitHub - select766/tanuki- at tanuki-dr4-learner
上記のビルド済みバイナリを使わず、自前でビルドする際の環境構築を示します。これは、やねうら王リポジトリ にあるmake-msys2.ymlを参考にしました。
まず、MSYS2をセットアップします。 https://www.msys2.org/ から、 msys2-x86_64-20240507.exe をダウンロードしてデフォルト設定でインストールします。
コマンドプロンプト を開き、以下のコマンドを実行して必要なライブラリをインストールします。
C:\msys64\usr\bin\bash.exe -lc 'pacman --needed --noconfirm -Syuu'
C:\msys64\usr\bin\bash.exe -lc 'pacman --needed --noconfirm -Syuu'
C:\msys64\usr\bin\bash.exe -lc 'pacman --needed --noconfirm -Syuu pactoys'
C:\msys64\usr\bin\bash.exe -lc 'pacboy --needed --noconfirm -Syuu clang:m lld:m openblas:x openmp:x toolchain:m base-devel:'
PowerShell を開き、以下のコマンドを実行してソースコード をダウンロード・ビルドします。
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process
$ENV:Path="C:\msys64;"+$ENV:Path
git clone -b tanuki-dr4-learner https://github.com/select766/tanuki-.git
cd tanuki-
.\script\msys2_build.ps1 -Edition YANEURAOU_ENGINE_NNUE -Compiler g++
ビルドが成功すると、 tanuki-\build\windows\NNUE\YaneuraOu_NNUE-evallearn-g++-sse42.exe などが得られます。
Tips
Set-ExecutionPolicy の行は、そのシェルを開いている間だけps1ファイルの実行を許可します。MSVCでのビルドはできませんでした。OpenMP のループ変数にunsigned intが使われている箇所があり、MSVCにとっては文法エラーとなりました。
nnue-pytorch
環境構築
※C++ コンパイラ については、手元ですでに入っていたものを利用したため、もしかしたらこの手順だとうまくいかないかもしれません。
C++ コンパイラ を入手するため、Build Tools for Visual Studio 2022をダウンロード・インストールします。(Visual Studio 2022をインストールしている場合は、「C++ によるデスクトップ開発」の機能を有効にすれば同等のものが手に入ると思われます)
Visual Studio Tools のダウンロード - Windows、Mac、Linux 用の無料インストール
Build Tools for Visual Studio 2022
cmakeをダウンロード・インストールし、パスが通った状態にします。
Download CMake
Python 環境として、Anaconda を用います。
Anaconda Promptで、以下のコマンドを実行して必要なツールをインストールします。
conda create --name nnue python=3.9
conda activate nnue
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install python-chess==0.31.4 pytorch-lightning==1.9.0 cshogi==0.8.5
conda install matplotlib
pip install tensorboard tensorboardX
以後、新しいAnaconda Promptを開くたびに conda activate nnue の実行が必要です。
nnue-pytorchをダウンロードします。 masterブランチはチェス用です
git clone -b shogi.2024-04-20.halfkp_1024x2-8-64 https://github.com/nodchip/nnue-pytorch
コマンドプロンプト を開き、PackedSfenValue形式の棋譜 を読むためのネイティブライブラリをビルドします。
cd path\to\nnue-pytorch
compile_data_loader.bat
ネットワーク構造の設定
上記でダウンロードした shogi.2024-04-20.halfkp_1024x2-8-64 ブランチは、nodchipさんが実験のためにモデル構造を変更したものなので、ここで学習したモデルは通常のやねうら王では動かせません。
やねうら王が対応している「標準NNUE」形式を学習する場合は、 model.py の冒頭を次のように書き換えます。標準NNUEは、 halfkp_256x2-32-32 と表記される形式となっています。
# 3 layer fully connected network
L1 = 256
L2 = 32
L3 = 32
学習
以下のコマンドで学習を行います。パスは適宜書き換えてください(最後の2つの引数が学習データ、 --default_root_dir がログの出力ディレクト リ)。
python train.py --features "HalfKP" --batch-size 16384 --max_epochs 1000000 --enable_progress_bar False --default_root_dir logs/20240526_halfkp_256x2-32-32 --threads 8 --lr 0.5 0.05 --num-workers 8 --lambda 1.0 0.5 --label-smoothing-eps 0.001 --accelerator gpu --devices 1 --score-scaling 361 --min-newbob-scale 1e-5 --epoch-size 1000000 --num-epochs-to-adjust-lr 500 --momentum 0.9 --network-save-period 1000 --resume-from-model "" "path\to\shogi_hao_depth9\train_shuffled\shuffled.bin" "path\to\shogi_hao_depth9\val_shuffled\shuffled.bin"
モデルの精度に関するオプションは、nodchipさんがWCSC34用の学習に用いたと説明された値を用いています。
学習のログやチェックポイントファイルは nnue-pytorch\logs\20240526_halfkp_256x2-32-32\lightning_logs\version_0 ディレクト リに吐き出されています。1000epoch(1epoch=1Mサンプル)ごとにチェックポイントを保存するようにしており、検証環境では約1時間ごとに保存されました。max_epochsに大きな値を指定してあるため、適当なタイミングで、Ctrl-Cにより終了する必要があります。
学習状況の確認
上記のコマンドではほぼコンソールに出力がされないので、tensorboardを用いて状況を確認する必要があります。
tensorboard コマンドを実行すると、Webブラウザ が開き、学習状況が可視化できます。
tensorboardの画面
モデルをやねうら王の形式に変換する
学習されたモデル(拡張子: ckpt)を、やねうら王で読み込める形式に変換する方法を解説します。
ここでは、先ほどのコマンドで1000epoch学習された時点のチェックポイント( logs\20240526_halfkp_256x2-32-32\lightnin
g_logs\version_0\1000.ckpt )を入力として、 for_yaneuraou\nn.nnueに出力します。ディレクト リは自動的に作られます。nn.nnue以外に画像ファイルが出力されるので、カレントディレクト リは避けたほうがよいです。後の処理を考えると、 nn.bin のほうが便利なのですが、拡張子がチェックされるため*.nnueを指定してください。
python serialize.py --features "HalfKP" logs\20240526_halfkp_256x2-32-32\lightnin
g_logs\version_0\1000.ckpt for_yaneuraou\nn.nnue
ここで得られたnn.nnueファイルがやねうら王で使える評価関数ファイルになります。サイズは標準NNUEの場合、64,217,072バイトになっているはずです。
ここからは、やねうら王で動作させる例を示します。
やねうら王V7.6.3のビルド済みバイナリ(YaneuraOu-v7.6.3-windows .7z)をダウンロード・解凍します。
github.com
実行ファイルは、 YaneuraOu-v7.6.3-windows\windows\NNUE\YaneuraOu_NNUE-normal-clang++-sse42.exe を使います。評価関数ファイルを以下のように配置します。
- YaneuraOu_NNUE-normal-clang++-sse2.exe
- eval
- nn.bin (※nn.nnueからリネーム)
あとは、 YaneuraOu_NNUE-normal-clang++-sse2.exe を将棋所などでエンジン登録すれば対局できます。
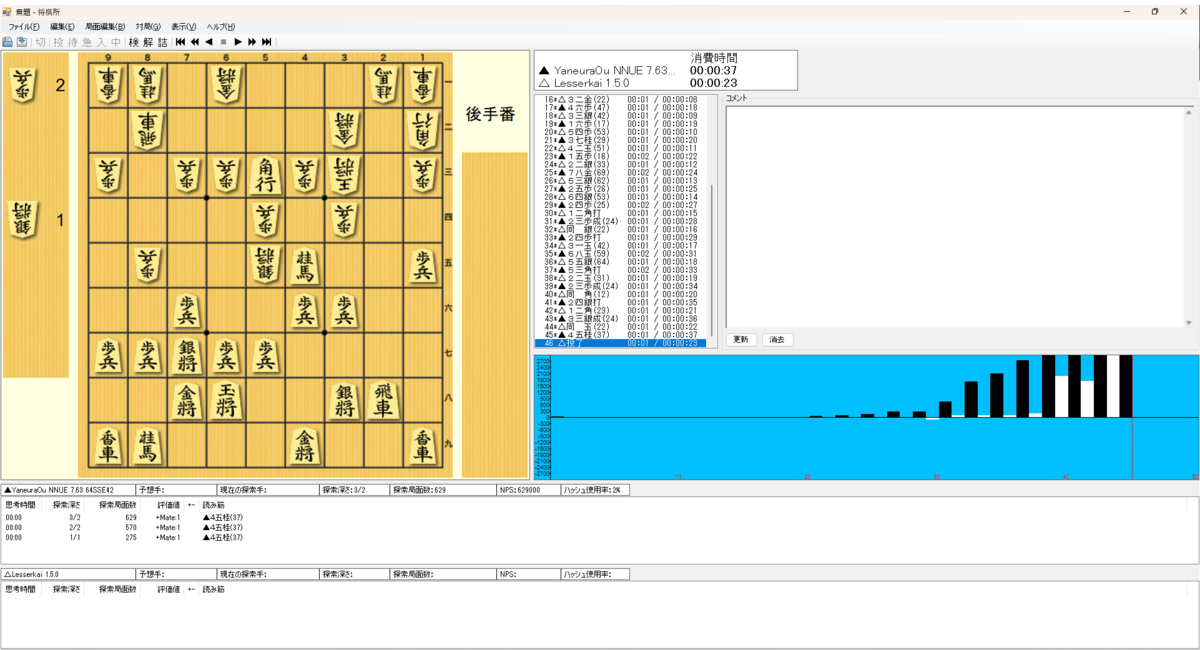
1000epoch学習したモデルを用いた対局のスクリーンショット を示します。初手は2六歩を指し、45手でLesserkaiに勝利しています。大会で使えるレベルの強さではないと思われますが、学習パイプラインが無事完成したことを確認できます。
学習したモデルとLesserkaiの対局
モデル構造を変化させる方法
nnue-pytorchでは、様々なモデルの構造(パラメータ数)を試すことができます。前述のように学習の際は"model.py"を変更します。学習結果をやねうら王で使えるようにするには、やねうら王の nnue_architecture.h がモデル構造を切り替えているため、これを書き換えてビルドする必要があります。
https://github.com/yaneurao/YaneuraOu/blob/b327a273c942ad24ee9666c427d92d391da7e4fa/source/eval/nnue/nnue_architecture.h#L54
まとめと今後の課題
Web上で公開されている棋譜 データセット を用いて、nnue-pytorchによりNNUE評価関数を学習させ、やねうら王で動作させるまでのパイプラインを示しました。
学習用の棋譜 の生成方法まで網羅できれば、完全に独自の評価関数を学習できるようになります。
NNUEについては私も詳しくない箇所が多く、誤りがあるかもしれません。誤りがあればご指摘お願いいたします。