前回、AlphaZero方式でモデルの学習が実現できました。しかしモデルの推論にTensorflowを用いていたため、CodinGameに投稿できるコードになりませんでした。ここからは、C++言語だけでモデルの推論ができるように実装を進めます。 C++言語からDNNモデルを推論できるインターフェースを備えた深層学習ライブラリはいくつかありますが、数百kB以上のライブラリを要するものが多く、10万文字の制限内に収めるには不向きなものが多いです。のちにTVMを用いた方法を紹介しますが、まずは今回のモデルに必要なロジックのみを備えたごく簡単な推論機構を独自に実装しました。
今回のコードのバージョンです。
https://github.com/select766/codingame-othello/tree/22be3edc6eb3fa1be113736a6ab6e7f9f9ec4dc1
Tensorflowのモデルから重みを抽出する
モデルの推論を独自に行うため、Tensorflowで学習されたモデルファイルから、重み行列の全要素の値を抽出します。これは、Python上でTensorflowを用いてモデルを解釈することで実現できます。以下のように、モデルの重みをnumpy配列として列挙することが可能です。
import tensorflow as tf model = tf.keras.models.load_model(args.savedmodel_dir) for w in model.weights: name = w.name # "othello_model_v1/conv2d_1/kernel:0" array = w.numpy() # numpy配列(np.float32)
重みが列挙される順番は、おそらくソースコード上の定義順に沿っています。w.nameは以下の順で出力されました。モデルの定義時に明示的にレイヤーの名前を与えれば対応関係がはっきりしますが、特定のモデルを手動で解釈する範囲で十分なのでこのまま進めます。
othello_model_v1/conv2d/kernel:0 othello_model_v1/conv2d/bias:0 othello_model_v1/conv2d_1/kernel:0 othello_model_v1/conv2d_1/bias:0 othello_model_v1/conv2d_2/kernel:0 othello_model_v1/conv2d_2/bias:0 othello_model_v1/conv2d_3/kernel:0 othello_model_v1/conv2d_3/bias:0 othello_model_v1/conv2d_4/kernel:0 othello_model_v1/conv2d_4/bias:0 othello_model_v1/conv2d_5/kernel:0 othello_model_v1/conv2d_5/bias:0 othello_model_v1/dense/kernel:0 othello_model_v1/dense/bias:0 othello_model_v1/dense_1/kernel:0 othello_model_v1/dense_1/bias:0
以下のコードで、すべての重みをバイト配列として連結し、それぞれの要素数も出力します。取り出した重みを、C++のソースコード中で文字列定数として埋め込める形にします。本来4バイト(float32)の重みを、1.23456のようなfloatの定数で書くとソースコードが長くなるため、バイト列として扱いbase64を用いて3バイトを4文字で表した文字列定数として埋め込むことにします。
struct_def = "" flat_binary = b"" for w in model.weights: name = w.name name = name.removeprefix("othello_model_v1/") name = name.removesuffix(":0") name = name.replace("/", "_") array = w.numpy() size = array.size struct_def += f"float {name}[{size}];\n" flat_binary += array.tobytes() print(struct_def) hpp_src = f"""#ifndef _DNN_WEIGHT_ #define _DNN_WEIGHT_ const char dnn_weight_base64[] = "{base64.b64encode(flat_binary).decode("ascii")}"; #endif """
hpp_srcは、すべての重みのバイト列をbase64により文字列定数化したものです。
const char dnn_weight_base64[] = "OvrLvTipPb40..."
struct_defは文字列定数をバイト列にデコードした結果を、テンソルごとに分離するための構造体定義になります。その例を示します。
class DNNWeight { public: float conv2d_kernel[216]; float conv2d_bias[8]; float conv2d_1_kernel[576]; float conv2d_1_bias[8]; float conv2d_2_kernel[576]; float conv2d_2_bias[8]; float conv2d_3_kernel[576]; float conv2d_3_bias[8]; float conv2d_4_kernel[576]; float conv2d_4_bias[8]; float conv2d_5_kernel[8]; float conv2d_5_bias[1]; float conv2d_6_kernel[64]; float conv2d_6_bias[8]; float dense_kernel[512]; float dense_bias[1]; };
これで、C++のソースコード内に学習された重みを埋め込める状態になりました。重みを埋め込んだファイルは、src/_dnn_weight.hppに書き出して他のソースからincludeします。
モデルの実行
モデルを実行する機構を実装します。まずテンソルを表現するクラスです。テンソルの次元数には4次元(畳み込みへの入力、畳み込みの重み)、2次元(全結合層への入力)、1次元(重みのバイアス)がありますが、4次元で統一し、不要な次元には1を代入することにしました。また、外部からメモリ領域を与える初期化と、クラス内でメモリ領域を確保する初期化の両方をサポートしました。using PTensor = shared_ptr<Tensor>;を定義し、クラス内でメモリを確保した場合は自動で解放するようにしました。
class Tensor { public: float *data; bool owndata = false; array<int, 4> shape; // 簡単のため常に4Dで扱う。(batch, h, w, c) or (batch, 1, 1, c) or (1, 1, 1, c) array<int, 4> strides; int size; Tensor(array<int, 4> shape, float *data = nullptr) : data(data), shape(shape) { size = 1; for (size_t i = shape.size() - 1; i < shape.size(); i--) { strides[i] = size; size *= shape[i]; } if (!data) { owndata = true; this->data = new float[size]; } } // クラス内でメモリを確保した場合は解放 ~Tensor() { if (owndata) { delete[] data; } } // 要素にアクセスする関数 float &v(int n, int h, int w, int c) { return data[n * strides[0] + h * strides[1] + w * strides[2] + c * strides[3]]; } float &v(int n, int c) { return data[n * strides[0] + c * strides[3]]; } float &v(int c) { return data[c * strides[3]]; } }; using PTensor = shared_ptr<Tensor>;
テンソルを用いた全結合層の実装は以下のように実装しました。素直な行列積の実装です。
PTensor dense(PTensor x, PTensor w, PTensor b) { // x: (n=1, 1, 1, in_c) // w: (in_c, 1, 1, out_c) // b: (1, 1, 1, out_c) // y: (n=1, 1, 1, out_c) PTensor y = tensor({1, 1, 1, w->shape[3]}); for (int n = 0; n < w->shape[3]; n++) { float sum = b->v(n); for (int k = 0; k < w->shape[0]; k++) { sum += x->v(k) * w->v(k, n); } y->v(n) = sum; } return y; }
畳み込み層はもう少し複雑ですが、定義通りの計算を実装しています。
PTensor conv2d(PTensor x, PTensor w, PTensor b, int pad, int stride) { // x: (n=1, h, w, in_c) // w: (kh, kw, in_c, out_c) // b: (1, 1, 1, out_c) // y: (n=1, out_h, out_w, out_c) int in_h = x->shape[1], in_w = x->shape[2], in_c = x->shape[3]; int kh = w->shape[0], kw = w->shape[1], out_c = w->shape[3]; int out_h = (in_h + 2 * pad - kh) / stride + 1; int out_w = (in_w + 2 * pad - kw) / stride + 1; PTensor y = tensor({1, out_h, out_w, out_c}); for (int out_y = 0; out_y < out_h; out_y++) for (int out_x = 0; out_x < out_w; out_x++) for (int oc = 0; oc < out_c; oc++) { float sum = b->v(oc); for (int ic = 0; ic < in_c; ic++) for (int ky = 0; ky < kh; ky++) for (int kx = 0; kx < kw; kx++) { int in_y = out_y * stride - pad + ky; int in_x = out_x * stride - pad + kx; if (in_y < 0 || in_y >= in_h || in_x < 0 || in_x >= in_w) { continue; } sum += x->v(0, in_y, in_x, ic) * w->v(ky, kx, ic, oc); } y->v(0, out_y, out_x, oc) = sum; } return y; }
これらの機能を用いて、モデルの実行機構を実装します。モデルの構造に沿って処理の順序を手書きで実装しています。学習済みの重みはDNNWeight weight構造体に入っており、先述のようにテンソルごとに分割されている状態のものをtensor({3, 3, 3, 8}, weight.conv2d_kernel)のように形状を指定してTensorクラスのオブジェクトとして扱えるようにします。
DNNEvaluatorResult evaluate(const Board &board) { DNNInputFeature req = extractor.extract(board); PTensor h = tensor({1, BOARD_SIZE, BOARD_SIZE, 3}, req.board_repr); h = conv2d(h, tensor({3, 3, 3, 8}, weight.conv2d_kernel), tensor({1, 1, 1, 8}, weight.conv2d_bias), 1, 1); relu_inplace(h); h = conv2d(h, tensor({3, 3, 8, 8}, weight.conv2d_1_kernel), tensor({1, 1, 1, 8}, weight.conv2d_1_bias), 1, 1); relu_inplace(h); h = conv2d(h, tensor({3, 3, 8, 8}, weight.conv2d_2_kernel), tensor({1, 1, 1, 8}, weight.conv2d_2_bias), 1, 1); relu_inplace(h); h = conv2d(h, tensor({3, 3, 8, 8}, weight.conv2d_3_kernel), tensor({1, 1, 1, 8}, weight.conv2d_3_bias), 1, 1); relu_inplace(h); h = conv2d(h, tensor({3, 3, 8, 8}, weight.conv2d_4_kernel), tensor({1, 1, 1, 8}, weight.conv2d_4_bias), 1, 1); relu_inplace(h); auto p = h, v = h; // policy head, value headへ分岐 p = conv2d(p, tensor({1, 1, 8, 1}, weight.conv2d_5_kernel), tensor({1, 1, 1, 1}, weight.conv2d_5_bias), 0, 1); v = conv2d(v, tensor({1, 1, 8, 8}, weight.conv2d_6_kernel), tensor({1, 1, 1, 8}, weight.conv2d_6_bias), 0, 1); relu_inplace(v); flatten_inplace(v); v = dense(v, tensor({512, 1, 1, 1}, weight.dense_kernel), tensor({1, 1, 1, 1}, weight.dense_bias)); DNNEvaluatorResult res; memcpy(res.policy_logits, p->data, sizeof(res.policy_logits)); memcpy(&res.value_logit, v->data, sizeof(res.value_logit)); return res; }
CodinGameへの投稿
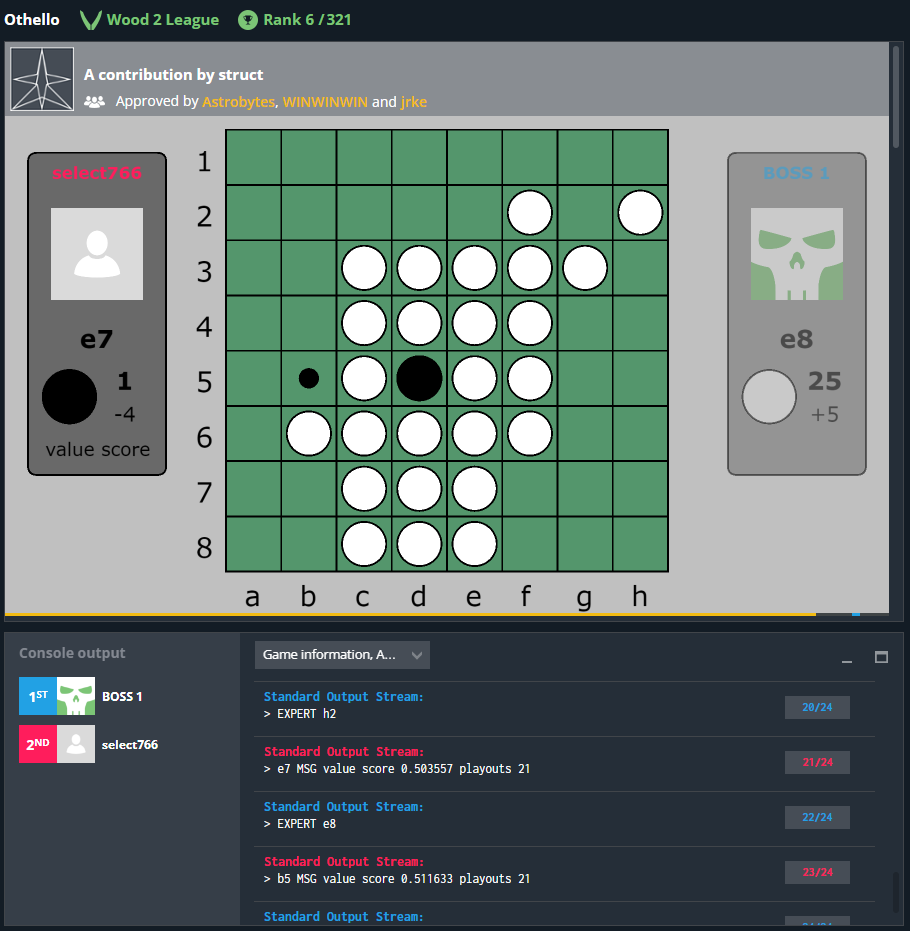
ついにAlphaZero方式で学習したモデルをCodinGameに投稿可能になりました。モデルのパラメータは、畳み込み5層(チャンネル数8)+policyに畳み込み1層+valueに畳み込み1層全結合1層です。Wood 2 Leagueで17位(石の数を評価値とし、アルファベータ法で探索するもの)から15位に上がりました。残念ながらあまり成績が向上しませんでした。対局サーバ上で、1手の思考中に10局面程度しか評価できていませんでした(制限時間120ms)。サーバ上でのコンパイル時に、デフォルトでは最適化がかからないようで遅い原因になっているようです。
モデルを少し大きくする
前章で投稿したソースコードは55kBで、CodinGameに投稿できる容量(10万文字)まで少し余裕があります。もう少し大きなモデルを学習しました。畳み込み7層(チャンネル数8)+policyに畳み込み2層+valueに畳み込み1層全結合1層の構成とし、さらにBatch Normalization層を追加しました。また、以下のpragmaをソースコード先頭に記述することで、若干最適化がかかり速度が向上することがわかりました(ただし、よりよいオプションがあります)。最適化なしの場合、1手の思考時間内に6局面、最適化ありの場合17局面の評価を行うことができました。
#pragma GCC optimize("O3,unroll-loops") #pragma GCC target("avx2,bmi,bmi2,lzcnt,popcnt")
投稿結果、Wood 2 Leagueで6位に上がりました。しかし、目視でわかる範囲でも打った手に難があり、全滅して負けるという事象が頻繁にみられました。次回は全滅対策を実装し、モデルをさらに大きくします。