実装
グラフィックの実装
前回作成したアセットを画面上に表示するための実装は、以下のようにして行えます。
#include <gb/gb.h> #include <gbdk/console.h> #include <gbdk/platform.h> // .cをincludeする。sizeof()を使いたいため。 #include "bg.c" #include "bg_map.c" #include "sprite.c" // VBLANK割り込みで呼ばれる void update() { // スプライトの座標x, yを計算 move_sprite(0, x, y); // スプライト0番を座標x, yに移動 } int main() { DISPLAY_OFF; // 液晶をオフ SHOW_BKG; // 背景を使用するフラグをセット SHOW_SPRITES; // スプライトを使用するフラグをセット set_bkg_data(0, sizeof(TileData) / 16, TileData); // VRAMに背景タイル画像を転送 set_bkg_tiles(0, 0, 20, 18, MapData); // VRAMに各座標に表示するタイルの番号を転送 set_sprite_data(0, sizeof(SpriteLabel) / 16, SpriteLabel); // VRAMにスプライト画像を転送 set_sprite_tile(0, 0); // スプライト0番にタイル0番を表示 DISPLAY_ON; // 液晶をオン __critical // 割り込み禁止 { add_VBL(update); // VBLANK割り込み時に呼び出される関数をセット } while (1) { wait_vbl_done(); // VBLANK割り込みが発生し、割り込み処理が完了するまで待機する // ここにスプライトの移動処理を実装してもよい } }
まず、main関数の先頭でグラフィックの設定および画像データ等の転送を行います。その後、move_sprite(uint8_t nb, uint8_t x, uint8_t y)関数により、nb番のスプライトを指定した座標(x, y)に移動することができます。x座標は、8のときにスプライトの左端と画面の左端が一致します。それより小さい値だと、スプライトの左側が画面外に隠れます。y座標は16のときにスプライトの上端と画面の上端が一致します。move_spriteなどのグラフィックの操作は、VRAMへのアクセスを伴います。グラフィックチップからのVRAMアクセスと競合しないようにするため、CPUからのVRAMアクセスは60fps(1秒間に60回)で発生するVBLANK割り込みが発生した直後に行う必要があります。アクセスのタイミングを計るには、VBLANK割り込み時に呼び出される関数をadd_VBL関数でセットするか、VBLANK割り込みの処理が完了するまで待機するwait_vbl_done関数を用います。
printfとの干渉を避ける
前節で実装した背景と、printfによる文字の表示は干渉してしまうという問題があります。背景を表示した後printfを用いると、文字が書かれた場所だけでなく画面全体から背景が消えてしまいます。printfはデバッグ用途を想定したものですが、学習したエピソード数などの文字の表示を独自に実装するのは手間がかかるため、背景を表示しつつprintfを併用する手段を検討しました。printfを最初に実行した際、背景タイル0番~101番にフォントデータが設定され、また画面全体に0番(空白)のタイルが設定されます。そのため、以下の2点のテクニックを用いることで併用が可能でした。(1)独自の背景に用いるタイルを128番から登録するようにしてフォントデータと共存させる、(2)printfを一度実行してから、背景のタイル番号を設定する。
背景に用いるタイル番号を128から始まるように変更するため、Pic2Tilesで出力されたソースコードを書き替えます。bg_map.cを開き、定数に128を加算してbg_map_offseted.cに保存します。
// 変更前 const unsigned char MapData[] = { 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x01,0x02, // 変更後 const unsigned char MapData[] = { 0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x80,0x81,0x82,
もちろん手作業では大変なので、Pythonで正規表現により実装しました。
re.sub(r'0x([0-9A-Fa-f]{2})', lambda m: '0x{:02X}'.format(int(m.group(1), 16) + 128), source)
結局、背景に文字を重ねて表示するコードは以下のようになります。
int main()
{
DISPLAY_OFF;
SHOW_BKG;SHOW_SPRITES;
printf("0"); // このタイミングでフォントデータのセットが行われる
set_bkg_data(128, sizeof(TileData) / 16, TileData); // 128番以降にタイル画像をセット
set_bkg_tiles(0, 0, 20, 18, MapData); // 独自の背景を表示
gotoxy(0, 16); // 次の文字が表示される座標を変更(画面下から2行目)
puts("Training...");
DISPLAY_ON;
}
スプライトも表示すると、以下のような画面が得られます。

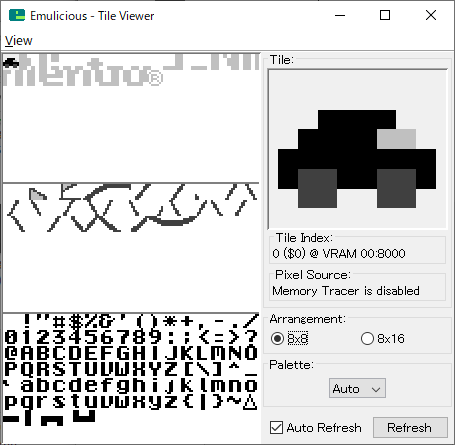
エミュレータでは、VRAM上のタイルデータを可視化することができます。車のスプライト、背景マップ、フォントが共存できています。車の右には、電源投入時に自動的にセットされるNintendoロゴのスプライトが残っています。
あとは、スプライトを適切に移動することで車が動いている様子を表示することが可能になります。











